はじめに
VOICEVOXが組込みシステムからでもすごく使いやすかったので、一つのデモストレーションとして最新ニュースをしゃべる装置という体でシステムを構築してみました。
対象読者
- 弊社の技術にご関心のある方
システム構成
実際に作成したデバイスのデモ
まずは下記のビデオをご覧ください。ボタンを押した後、ニュースを音読します。声はずんだもんを使用しています。
使用した主なサービスやライブラリ
使った主なサービスやライブラリは以下の通りです。
- VOICEVOX
- NewsAPI
- NHKウェブサイト
- nokogiri(ruby gem)
- oscgonfer/AudioI2S(ESP32用オーディオプレイヤライブラリ)
システム構成
今回製作したシステムは、ローカルサーバ、IoTデバイスから成ります。必要に応じてインターネット側のサービスを利用しています。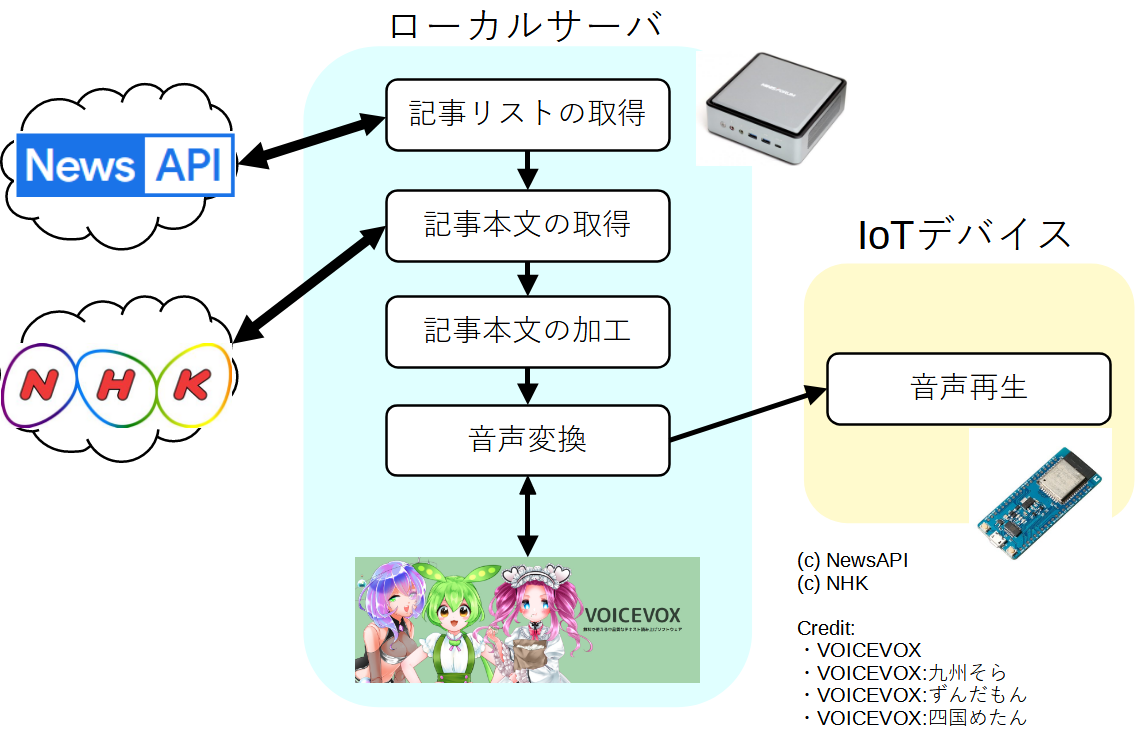
VOICEVOXおよび音声データ編集に使ったSOXの処理が重いため、今回のローカルサーバはMINISFORUM EliteMini HM80 (AMD Ryzen 4800U (8core/16thread)/16GB-mem/500GB-SSD)を使いました。IoTデバイスには ESPr® Developer 32(ESP-WROOM-32)に音声発生用のD級アンプ(MAX98357A)を組み合わせました。
ローカルサーバ側の処理
図にある通り、ローカルサーバでは最新ニュースリストの取得から、音声データの生成までを実行します。
最新ニュースリストはNewsAPIにアクセスして取得します。取得した内容は以下の通りJSON形式で得られます。この中からauthor, title, urlの要素の情報を利用します。
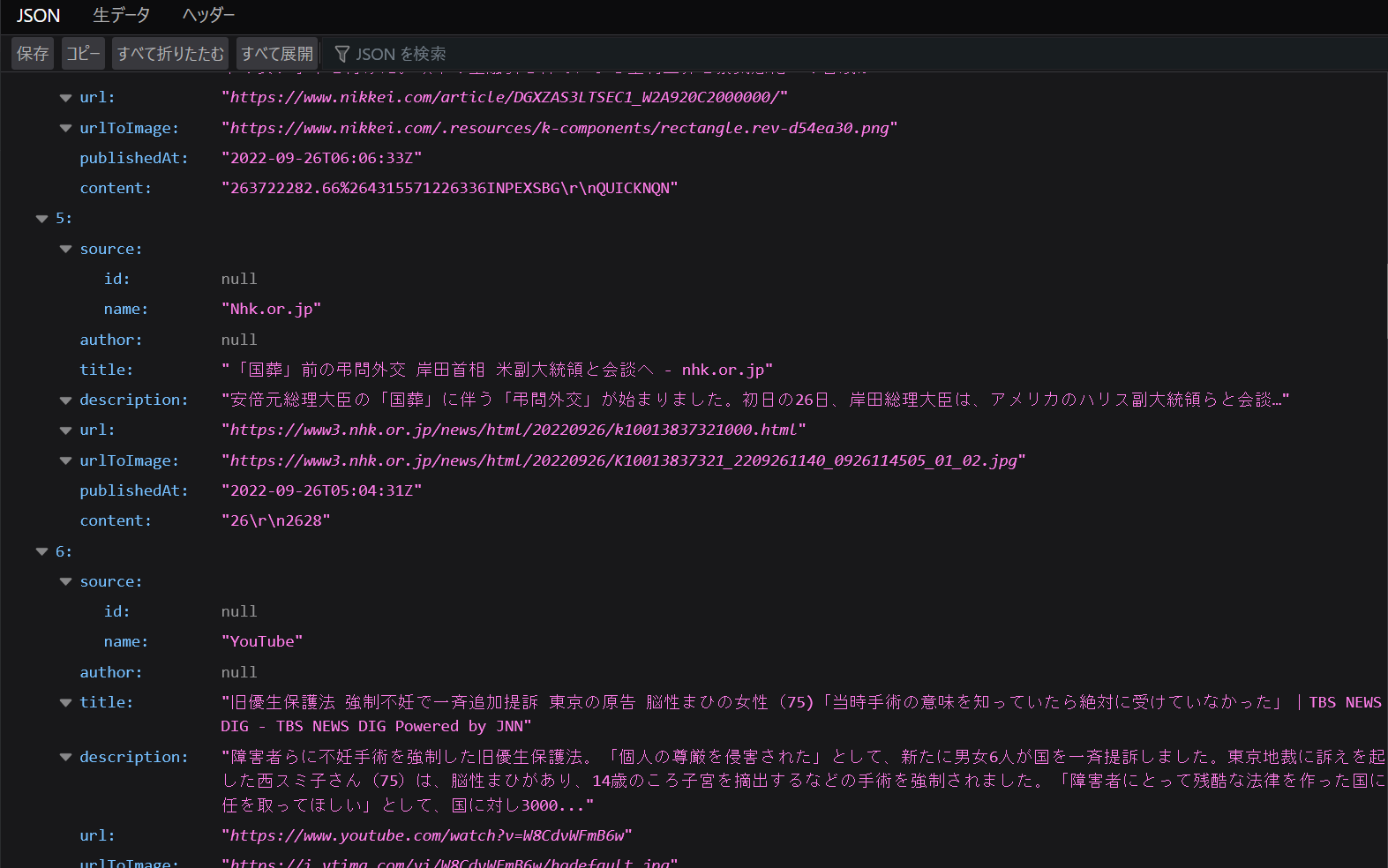
次に各ニュースの本文を取得します。ニュースはurl要素の値が指すウェブページにありますが、これはHTMLで記述されており、ニュースを提供する各社で記述方法が異なります。そのため、複数のニュース提供会社に対応しようとすると、それだけ記事本文の加工のための個別操作が必要になりますので、今回はNHKのニュースにだけ対応するようにしました。
最新ニュースリストにあるurlからニュース本文があるウェブページにアクセスすると以下のようなページが得られます。
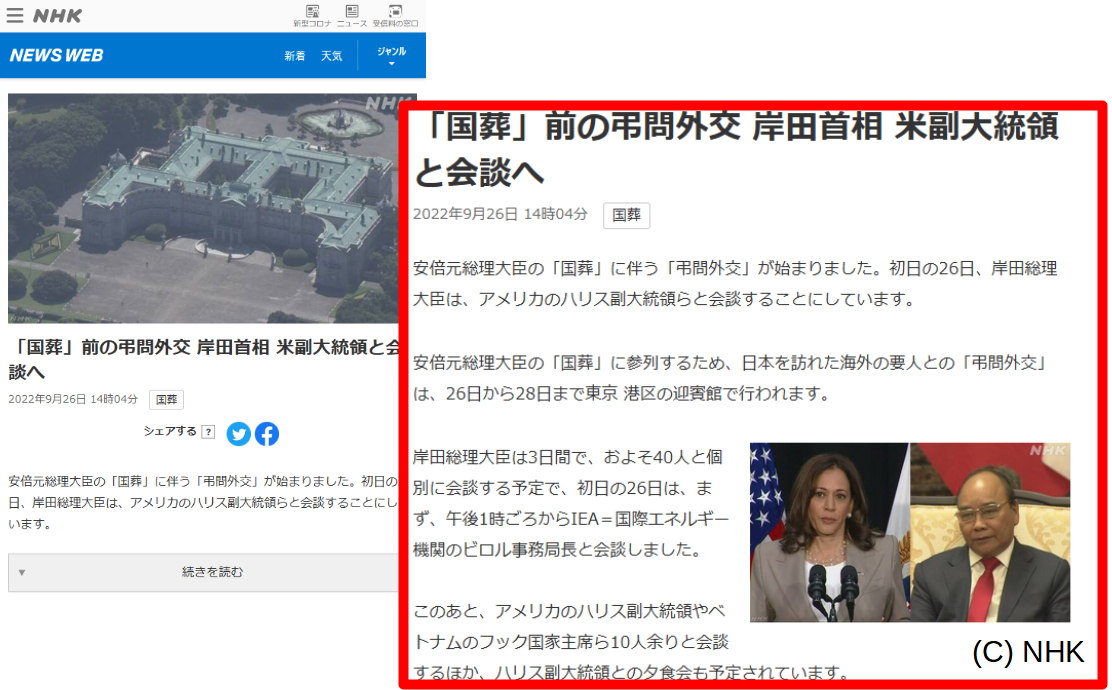
この赤で囲った部分のあたりのHTMLソースコードは以下の通りです。
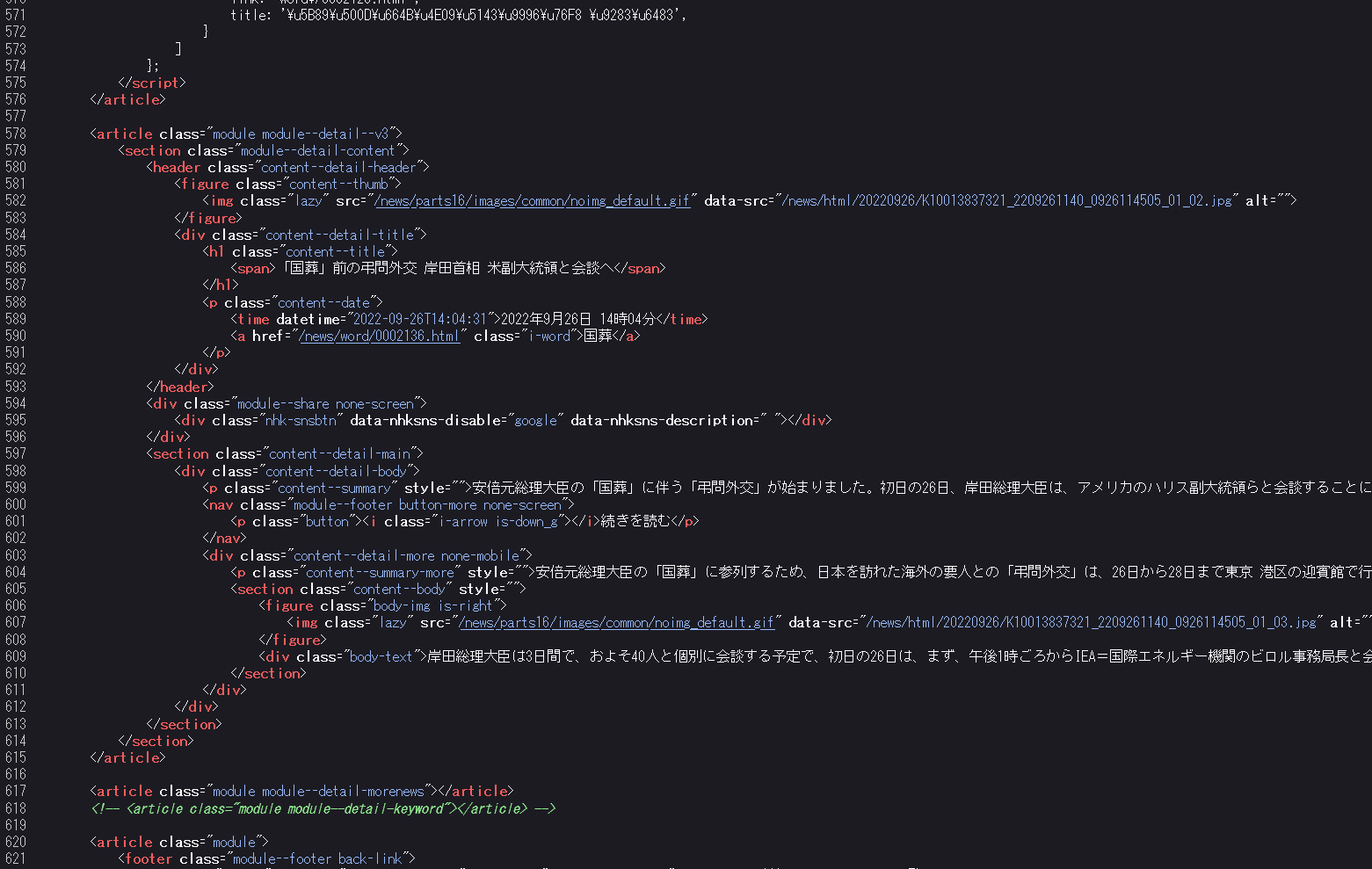
この中の真ん中あたりにある<div class="content--detail-more none-mobile">...</div>に本文があります。この部分を切り出すと以下のような内容になります。
<div class="content--detail-more none-mobile">
<p class="content--summary-more" style="">
安倍元総理大臣の「国葬」に参列するため、日本を訪れた海外の要人との「弔問外交」は、26日から28日まで東京 港区の迎賓館で行われます。
</p>
<section class="content--body" style="">
<figure class="body-img is-right">
<img class="lazy" src="/news/parts16/images/common/noimg_default.gif" data-src="/news/html/20220926/K10013837321_2209261140_0926114505_01_03.jpg" alt="">
</figure>
<div class="body-text">
岸田総理大臣は3日間で、およそ40人と個別に会談する予定で、初日の26日は、まず、午後1時ごろからIEA=国際エネルギー機関のビロル事務局長と会談しました。<br /><br />このあと、アメリカのハリス副大統領やベトナムのフック国家主席ら10人余りと会談するほか、...(略)
</div>
</section>
</div>
次に本文加工において、発話中の息継ぎなどをコントロールするための句読点や<br>タグ、<p>タグの直前に改行コードの挿入、タグの削除を行います。冒頭にはニュースのタイトルおよび「NHKより。」という言葉を追加して、以下のテキストを得ます。
「国葬」前の弔問外交、
岸田首相、
米副大統領と会談へ。
NHKより。
安倍元総理大臣の「国葬」に参列するた め、
日本を訪れた海外の要人との「弔問外交」は、
26日から28日まで東京港区の迎賓館で行われます。
岸田総理大臣は3 日間で、
およそ40人と個別に会談する予定で、
初日の26日は、
まず、
午後1時ごろからIEA=国際エネルギー機関のビロル事務局長と会談しました。
このあと、
アメリカのハリス副大統領やベトナムのフック国家主席ら10人余りと会談するほか、
ハリス副大統領との夕食会も予定されています。
...(略)
ここまで出来たら、VOICEVOXのAPIにアクセスして、1行ずつ音声合成データに変換し、空行は0.5秒の無音データとして一時保存を行い、最後にsoxでニュース全体を一つの音声ーデータにまとめます。
最後にlighttpdのdocker containerのデータディレクトリに音声データとデータリストのファイルを置きます。
IoTデバイス側の処理
ESP32はWiFiの機能を持っていますので、これを利用して先に説明したローカルサーバ上のウェブサーバにアクセスして、音声データのファイルリストを得ます。次に schreibfaul1/ESP32-audioI2Sのライブラリを利用して、ウェブサーバからデータをダウンロードしながら再生します。このライブラリを使用すれば、特に難しい点はありません。
VOICEVOX
VOICEVOX API
VOICEVOXはユーザインターフェス付きの実行ファイルとVOICEVOX-COREと呼ばれるユーザインターフェースなしの実行ファイルが提供されています。どちらもウェブインターフェースのAPIを持っていて、実行ファイルを立ち上げると音声合成サービスを提供するウェブサーバとしても機能します。今回は組込み用を想定していたので、VOICEVOX-COREを同梱したdocker containerを使いました。使い方はこちらのページなどを参照してください。
VOICEVOXとそのほかの音声合成システム
VOICEVOXとその他音声合成システムを比較した表を以下に示します。
| 比較項目 | VOICEVOX | システムA (Vocaloid等) |
システムB (Google/Azure等) |
|---|---|---|---|
| 音声の品質 | 〇 | ◎ | 〇 |
| 話者の数 | ◎ | ◎ | △ |
| 生成手順 | 自動 | 手動 | 自動 |
| ローカル対応 | ◎ | × | × |
| 使用料 | 無料(条件有) | 有料 | 有料 |
| 応用例 | Vtuber, ゆっくり劇場 |
スマートスピーカ, チャットボット |
こんな感じで、プログラムから呼び出して、テキストを自動で音声合成し再生させようと思うと、今のところVOICEVOXかクラウドサービスしかないです。また、インターネットから切り離された所での実装や、複数話者による会話の実装などになるとクラウドサービスも利用しづらくなります。そんな場合でも、VOICEVOXなら利用可能です。
課題
- NewsAPIで提供されるニュースの提供元が多数に及び、かつニューステキストを提供しないところもあるので、全部の対応は不可能です。今回はサンプルとしてNHKだけに対応しました。
- VOICEVOXとSOXがそこそこCPU時間を使います。VOICECOXはGPU対応なので、RTX3060くらいを用意できればかなり早くなります。また、フレーズ単位で音声合成と発話をパイプライン的に実装すれば会話のようなやり取りも可能だと思います。SOXの方は呼び出し方を工夫するともっと速くなりそうです。
- 今回は発話だけしかしていないので、音声UIのためには音声入力の対応も必要です。
まとめ
- VOICEVOXを使うと、事前に用意できずその場で生成するような文章でも音声合成・発話が可能であることを確認しました。
- 実空間上におけるUI/UXに対するVOICEVOXを使った音声ガイドなどの音声利用が現実的であることを示しました。
- 課題はありますが、ディスプレイパネルだけでは情報提供が不十分な場面がありますので、そんな時に音声によるUIが使えたらいいなと思います。